In part 1 I focused on the reason behind this blog, provided an overview of our implementation and I discussed the details of HPE StoreVirtual Multi-Site. Now it is time to focus on the details of vMSC, what happens when site to site communication is no longer possible, the issues we faced and finally I will provide an overview of the documentation used.
vMSC configuration
Now that we have an understanding on how we have built the storage part it is time to discuss the vMSC part. I will highlight the differences between our implementation of vMSC and the VMware vSphere Metro Storage Cluster Recommended Practises.
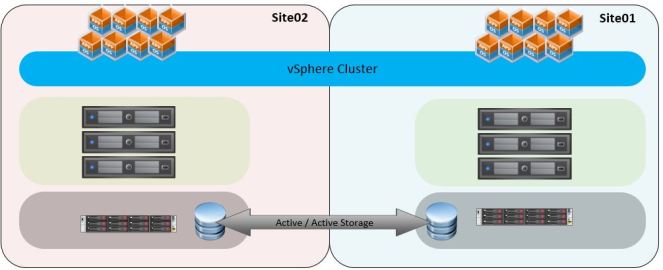
As explained earlier vMSC is the VMware certified solution for stretched storage cluster configurations. vMSC is typically deployed in environments where the distance between datacenters is limited. vMSC infrastructures are implemented to provide high availability beyond a single site. It is basically a stretched vSphere cluster where the storage (and the network) is also stretched and available in multiple sites. The main benefit of this configuration is that workloads can be balanced between sites and VM’s can run on both sites. vMSC is not a disaster recovery solution and VMware does not recommend to use vMSC as a disaster recovery solution. The picture below shows the vMSC solution. There is active/active storage and one big vSphere cluster which consists of 6 ESXi hosts (3 from each site). HA and DRS can be used to support high availability and load balancing. vMotion can also be used to do live migrations of VM’s from one site to another.
Software and version used
VMware vCenter Server 6.0 Update 2 and ESXi 6.0 Update 2 are used.
High Availability – Admission Control Policy
Admission control is used to make sure there are enough resources available when one site is not available. The below recommendations are gathered from the VMware documentation. We implemented these recommendations.
- VMware recommends enabling vSphere HA admission control
- To ensure that all workloads can be restarted by vSphere HA on just one site, configuring the admission control policy to 50 percent for both memory and CPU is recommended
- VMware recommends using a percentage-based policy
High Availability – Additional isolation addresses
Additional isolation addresses are used for ESXi to determine if it is isolated from its HA master node or completely from the network. The below recommendations are gathered from the VMware documentation. We implemented these recommendations. We have added two additional isolation addresses. The addresses we added are IP-addresses of both storage nodes.
- VMware recommends specifying a minimum of two additional isolation addresses, with each address site local.
High Availability – Heartbeat Datastores
As you may know HA uses two mechanisms to determine the status of a host. One is network heartbeating and the other is datastore heartbeating. Datastore heartbeating is only used when network heartbeating failed. The below recommendations are gathered from the VMware documentation. I have highlighted one of these recommendations because we did not implement this one.
The reason for this is that in a vMSC you should configure LUN site locality. This means that you configure a couple of LUN’s in one site to run primary on the storage node in the same site. And off course a couple of LUN’s in the other site to run primary on the storage node in that site. As I described earlier LUN’s on HPE StoreVirtual Multi-Site cannot be configured with site locality. The only thing you can configure is a primary site, but this means in case of a site to site connection failure all LUN’s will be made available in the primary site and access to these LUN’s will be stopped in the other site. Since we have no option to choose two LUN’s from site01 and two from site02 we couldn’t follow this recommendation.
- VMware recommends increasing the number of heartbeat datastores from two to four in a stretched cluster environment.
- Defining four specific datastores as preferred heartbeat datastores is also recommended, selecting two from one site and two from the other. This enables vSphere HA to heartbeat to a datastore even in the case of a connection failure between sites.
- To designate specific datastores as heartbeat devices, VMware recommends using Select any of the cluster datastores taking into account my preferences.
High Availability – VMware Component Protection (VMCP)
VMware Component Protection protects virtual machines from storage related events, specifically Permanent Device Loss (PDL) and All Paths Down (APD) incidents. The below recommendations are gathered from the VMware documentation. I have highlighted one of these recommendations because we did not implemented this one.
We configured the “Response for Datastore with All Paths Down (APD): Power off and restart VMs (aggressive). When a site to site connection failure occurs all ESXi hosts in site02 experience the APD scenario. Because this also means there is a network partition the VM’s are started in site01 (the one marked as primary in HPE StoreVirtual Multi-Site). Because they are started in site01 we need to make sure the “original” VM’s in site02 are terminated. I added two links in the “Reference Documents and Links” section of this blog regarding this subject. One blog explains VMCP and the other blog explains when you should use conservative and when aggressive.
- VMware recommends enabling VM Component Protection (VMCP)
- Response for Datastore with Permanent Device Loss (PDL): VMware recommends setting this to Power off and restart VMs
- Response for Datastore with All Paths Down (APD): VMware recommends configuring it to Power off and restart VMs (conservative)
- Response for APD recovery after APD timeout is: VMware recommends leaving this setting disabled
vSphere Dynamic Resource Scheduler (DRS)
DRS is used to balance the load in the vSphere cluster. By using VM-to-host affinity rules we can determine which VM’s we want to run in site01 and which we want to run in site02. The below recommendations are gathered from the VMware documentation. I have highlighted one of these recommendations because we did not implement this one.
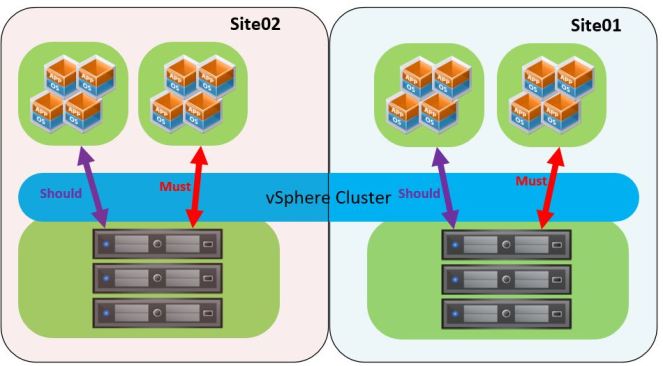
We did not implement this recommendation because we cannot configure LUN’s with site locality (as described above). We did create VM-to-host affinity rules to make sure certain VM’s (like Active Directory) are spread between sites. Here we use ”Should” rules because these can be violated in case of a site failure. We also have a very specific service we deliver to one of our clients which requires us to run certain VM’s in site01 and others in site02. These VM’s are not allowed to run in the other site. Here we use “Must” rules to make sure this does not happen.
- VMware recommends enabling vSphere DRS to facilitate load balancing across hosts in the cluster
- VMware recommends implementing vSphere DRS affinity rules to enable a logical separation of VMs
- VMware recommends aligning vSphere VM-to-host affinity rules with the storage configuration—that is, setting VM-to-host affinity rules with a preference that a VM runs on a host at the same site as the array that is configured as the primary read/write node for a given datastore
- VMware recommends implementing “should rules” because these are violated by vSphere HA in the case of a full site failure
- VMware recommends configuring vSphere HA rule settings to respect VM-to-host affinity rules where possible
- VMware recommends manually defining “sites” by creating a group of hosts that belong to a site and then adding VMs to these sites based on the affinity of the datastore on which they are provisioned
The picture below illustrates the DRS rules. Remember: VM’s configured with “Should” rules are allowed to violate the these rules in case of a site failure and VM’s configured with “Must” rules are not allowed to violate these rules.
Site to Site link failure
Off course the environment is built as a proof of concept first. We tested all kinds of scenario’s and the results are as described in the VMware documentation. However one scenario is different. You might have guessed it already because all recommendations from VMware which we did not follow are all related to the inability to configure LUN’s with site locality.
Remember the reason for this blog:
The above information is exactly the reason for this blog. Because the storage solution is truly active-active and there is no possible way to designate a particular LUN to a site (so no site locality) the failure scenario in case where the site to site link is lost is not as described in the VMware vMSC documentation. HPE describes 13 tested failure scenario’s but losing communication between sites is not one of them.

Let me talk you through this scenario and explain what happens when site to site communication is lost.
In this scenario the ESXi and HPE StoreVirtual nodes are unable to communicate with each other. Because site01 one is marked as primary the LUN’s are only accessible by the ESXi servers in Site01. LUN access for the ESXi hosts in Site02 is suspended. These hosts now experience a APD scenario. All VM’s which were running in site02 and are not configured with DRS Must rules are now being restarted at site01. This is exactly what we want 😀 .
Issues during testing
Another reason for this blog was:
This blog will provide information for setting up a vMSC with HPE StoreVirtual using the vSphere 6.0 Update 2 and HPE Lefthand 12.6. It will also describe the issues we faced while designing, building and testing the environment.
Now that we talked about the site to site link failure it is time to talk about the issues we faced (and are still facing). While we are very happy with the results in the case of a site to site link failure we were at first not happy with the restore process. Let me explain what I mean.
As soon as the site to site connection is restored we ended up with duplicate VM’s. There are two reasons for this:
- The ESXi hosts in Site02 experience a APD scenario when site to site communication fails. We configured VMCP to Power off and restart VMs (aggressive). So ESXi should terminate all VM’s on datastores experiencing APD at all times. However this is not working in our environment
- In case of duplicate VM’s vCenter should always kill the VM which no longer has a lock on the datastore. This also does not seem to be working in our environment.
Because the above issues were very disappointing and prevented us to continue to build the environment for production we opened a support call with VMware. I also contacted Duncan Epping from VMware hoping he could help us.
The first error is still under investigation by VMware support and this blog will be updated as soon as the case is closed. I deliberately say closed instead of resolved because Duncan and the engineering team from VMware think this issue cannot be resolved in our case. But the case is still open and I will update this blog as soon as there is anything new. The reason VMware thinks this cannot be resolved is because this has to do with datastore heartbeating. Because we cannot designate a particular LUN to a site (site locality again) the heartbeating mechanism is not working because it is not detecting a network partition.
The second issue is resolved. When we did our tests we created a couple of “empty” VM’s. By empty VM’s I mean VM’s with no guest operating system installed on it. So when the site to site connection is restored we had duplicate VM’s and none of them were killed. VMware support suggested to install a guest operating system (closer to real world situation) and start testing again. With a guest operating system installed duplicate VM’s are killed. It turns out “empty” VM’s do not generate I/O on the disk making it impossible to kill a VM.
In the “Reference Documents and Links” section of this blog I added a link in which both issues are explained in more detail.
For us it is no big deal if the APD problem cannot be resolved. The VM’s in site02 lose access to the storage so in a site to site link failure situation the VM’s “hang” and cannot be accessed. When the site to site link is restored these VM’s are being killed and DRS takes care of balancing the load.
Conclusion
I found it very interesting to design and built this environment. At first I was a bit disappointed about the lack of up-to-date documentation from HPE about vMSC in combination with StoreVirtual Multi-Site but now I’m very happy with the results. Maybe it is not ideal that the VM’s are not getting killed in an APD situation, but at least we have created an environment which is highly available and recovers itself after most types of failures.
I would also like to thank Duncan Epping for helping us out with the issues we faced. I contacted Duncan using LinkedIn and I was surprised he was willing to help me out. When the support case was not going very well he was able to get it back on track for us. I believe all that talk about customer feedback is important at VMware events really is true.
Reference documents and links
| Document | Filename |
| VMware vSphere Metro Storage Cluster Recommended Practices V3.0 May 2016 | vmware-vsphere-metro-storage-cluster-recommended-practices-white-paper.pdf |
| VMware vSphere Metro Storage Cluster on StoreVirtual Multi-Site SAN | VMware vSphere Metro Storage Cluster on StoreVirtual Multi-Site SAN.pdf |
| Implementing VMware vSphere Metro Storage Cluster with HP LeftHand Multi-Site storage | Implementing VMware vSphere Metro Storage Custer with HP LeftHand Multi-Site Storage.pdf |
| HPE StoreVirtual Storage Multi-Site Configuration Guide Edition 11 May 2016 | HPE StoreVirtual Storage Multi-Site Configuration Guid.pdf |

Hi,
Nice article. But i have two questions.
1. Can you tell me wich Licence you have used?
2. Do you have one or two vCenter Server (aka one per Side)?
Kind regards
LikeLike
Enterprise+, just one vcenter
LikeLike
And what happens if the Host with the vCenter die?
Who restart the VM’s on the other host?
LikeLike